Czy mogę sprawdzić jak robot Google widzi moją stronę?
Tak, wersja strony z pamięci podręcznej cache przedstawi Ci podgląd jak robot Google widział Twoją stronę ostatni raz gdy ją odwiedził.
Google przeszukuje i zapisuje w pamięci podręcznej cache strony w innym odstępie czasowym. Strony internetowe z dużym autorytetem i popularnością jak onet.pl będą znacznie częściej crawlowane w porównaniu do mniej znanych i mniej zaufanych stron i blogów.
Możesz zobaczyć wersję strony z pamięci przeglądarki cache poprzez rozwinięcie menu klikając strzałeczkę obok nazwy domeny, następnie klikając “cached”

Możesz także wyświetlić tekstową wersję witryny, aby ustalić, czy ważna treść jest skutecznie crawlowana i indeksowana.
Czy strony są kiedykolwiek usuwanie z indeksu Google?
Tak! Oczywiście, że strony mogą zostać usunięte z indeksu. Jest kilka przyczyn, przez który adres URL może zostać usunięty z indexu:
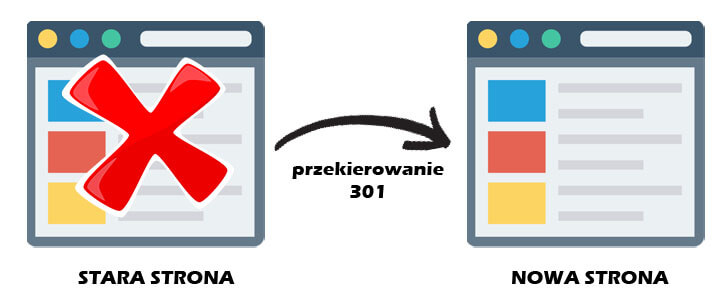
- URL zwraca błąd 404 (nie znaleziono), bądź błąd serwera (5xx) – takie zdarzenie może być przypadkowe( strona została przeniesiona bez zastosowania przekierowania permamentnego 301), lub celowe (strona została usunięte i zwraca błąd 404 w celu usunięcia jej z indexu).
- Adres URL ma zastosowany tag “noindex” – Taki tag może zostać zastosowany przez właściciela strony w celu poinstruowania wyszukiwarki, aby nie indexowały danego adresu URL
- Adres URL został ręcznie ukarany za naruszenie wskazówek dla webmasterów w wyniku czego został usunięty z indexu Google.
- Adres URL został zablokowany przez robotami crawlujący przy użyciu hasła (np. strony logowania)
Jeśli uważasz, że Twoja strona, która była wcześniej w indeksie Google, już się w nim nie znajduje, możesz użyć narzędzia do sprawdzania adresów URL, aby dowiedzieć się o stanie strony, lub użyć narzędzia Pobierz jako Google, które ma funkcję „Poproś o indeksowanie”, aby przesłać poszczególne adresy URL do indeksu. (Bonus: narzędzie „pobierz” w GSC ma również opcję „renderowania”, która pozwala sprawdzić, czy występują problemy z renderowaniem strony przez Google).
Powiedz wyszukiwarkom jak mają indeksować Twoją witrynę
Dyrektywy wpływają na indeksowanie, nie na crawlowanie
Googlebot musi zaindeksować Twoją stronę, aby zobaczyć jej meta-dyrektywy, więc jeśli próbujesz uniemożliwić robotom dostęp do niektórych stron, meta-dyrektywy nie są na to dobrym sposobem . Tagi robotów muszą być indeksowane/zauważone, aby były przestrzegane
Dyrektywy meta dla robotów
Mera dyrektywy (lub “meta tagi = znaczniki meta”) są instrukcjami, które możesz dać wyszukiwarkom w zależności od tego, jak chcesz aby traktowały Twoją stronę internetową.
Możesz powiedzieć wyszukiwarkom np. “Nie indeksuj tej strony w wynikach wyszukiwań” lub “Nie przesyłaj mocy do żadnego linku na tej podstronie”. Te instrukcje są wykonywane przez Znaczniki Meta w znaczniku HTMl Twojej strony (najczęściej używane) lub przez X-Robots-Tag w nagłówku HTTP.
Znaczniki meta dla robotów
Znaczniki meta mogą zostać zaimplementowane w sekcji w HTML’u na Twojej stronie internetowej. Mogą wykluczyć wszystkie lub określone wyszukiwarki. Poniżej przedstawimy najczęściej stosowane meta-dyrektywy wraz z sytuacjami, w których można je zastosować.
index/noindex – informuje wyszukiwarki, czy strona powinna zostać przeszukana i zapisana w indeksie wyszukiwarek do pobrania. Jeśli zdecydujesz się użyć „noindex”, komunikujesz się z robotami indeksującymi, że chcesz wykluczyć stronę z wyników wyszukiwania. Domyślnie wyszukiwarki zakładają, że mogą indeksować wszystkie strony, więc użycie wartości „index” nie jest konieczne.
- Kiedy można użyć: możesz oznaczyć stronę jako “noindex”, gdy chcesz aby strony z bezwartościowych contentem nie był indeksowane przez wyszukiwarkę, lecz chcesz aby użytkownicy mogli na nie wejść np.: strony profilowe
follow/nofollow – dają znak wyszukiwarkom czy roboty mają podążać “follow” czy nie mają podążać “ofollow” za linkami na tej stronie przekazując moc domeny (“link equity”) dalej przez te adresy URL. Jeżeli wybierzesz “nofollow”, roboty Google nie będą podążać dalej za linkami na danej podstronie, ani nie będą przekazywać przez nie mocy domeny. Domyślnie wszystkie strony posiadają atrybut “follow”.
- Kiedy można użyć: nofollow jest często używany razem z noindex, gdy próbujesz zapobiec indeksowaniu strony, a także uniemożliwić robotowi podążanie za linkami na stronie.
noarchive służy do ograniczenia przez wyszukiwarki zapisywania kopii strony w pamięci podręcznej. Domyślnie wyszukiwarki zachowają widoczne kopie wszystkich stron, które zaindeksowały, dostępne dla wyszukiwarek poprzez link z pamięci podręcznej w wynikach wyszukiwania.
Kiedy można użyć: Jeśli prowadzisz sklep e-commerce, a Twoje ceny regularnie się zmieniają, możesz rozważyć użycie tagu noarchive, aby zapobiec wyświetlaniu użytkownikom nieaktualnych cen w wynikach wyszukiwania.
Oto przykładowe zastosowanie atrybutu noindex, nofollow:
…
Ten przykład wyklucza wszystkie wyszukiwarki z indeksowania strony i podążania za linkami na stronie. Jeśli chcesz wykluczyć wiele robotów, na przykład googlebot i bing, możesz używać wielu tagów wykluczania robotów.
Tagi x-robots
Tag x-robots jest używany w nagłówku HTTP twojego adresu URL, zapewniając większą elastyczność i funkcjonalność niż metatagi. Jeśli chcesz blokować dostęp robotom do wybranych stron na dużą skalę, możesz wykorzystać wyrażenia regularne i blokować pliki inne niż HTML oraz stosować tagi noindex na całej stronie .
Na przykład możesz łatwo wykluczyć całe foldery lub typy plików (np. Moz.com/no-bake/old-recipes-to-noindex):
Przykład: Header set X-Robots-Tag “noindex, nofollow”
Lub określone typy plików (np. Pliki PDF):
Header set X-Robots-Tag “noindex, nofollow”
Aby uzyskać więcej informacji na temat metatagów Robot, zapoznaj się ze Specyfikacjami meta tagów Google Robots.
Porada dla użytkowników WordPressa!
W Ustawienia>Czytanie miej pewność, że box „Proś wyszukiwarki o nieindeksowanie tej witryny” jest NIE zaznaczony. Blokuje on dostęp robotom wyszukiwarek do Twojej strony www przez plik robots.txt
Zrozumienie jak różne czynniki wpływają na crawlowanie i indeksowanie pomoże Ci uniknąć typowych problemów, które mogą uniemożliwić odnalezienie robotom ważnych stron.
Pozycje: Jak wyszukiwarki internetowe pozycjonują Twoje adresy URL?
W jaki sposób wyszukiwarki odnajdują właściwą odpowiedź na pytanie szukającego? Proces ten nazywany jest rankingiem lub kolejnością wyników wyszukiwania według najbardziej odpowiednich do najmniej istotnych dla konkretnego zapytania.

Aby określić trafność zapytania, wyszukiwarki wykorzystują algorytmy, procesy, dzięki którym przechowywane informacje są pobierane i porządkowane w logiczny sposób. Algorytmy te przeszły wiele zmian na przestrzeni lat w celu poprawy jakości wyników wyszukiwania. Na przykład Google dokonuje korekt algorytmów każdego dnia – niektóre z tych aktualizacji są drobnymi poprawkami jakości, podczas gdy inne są podstawowymi / szerokimi aktualizacjami algorytmów wdrożonymi w celu rozwiązania określonego problemu, na przykład Penguin w celu usunięcia spamu linkowego. Sprawdź naszą historię zmian algorytmu Google, aby uzyskać listę zarówno potwierdzonych, jak i niepotwierdzonych aktualizacji Google od 2000 roku.
Dlaczego algorytm zmienia się tak często? Chociaż Google nie zawsze ujawnia szczegóły, dlaczego robią to, co robią, wiemy, że celem Google przy dostosowywaniu algorytmów jest poprawa ogólnej jakości wyszukiwania. Dlatego w odpowiedzi na pytania o aktualizację algorytmu, Google odpowie następująco: „Cały czas pracujemy nad jakością wyników wyszukiwań”. Oznacza to, że jeśli Twoja witryna ucierpiała po dostosowaniu algorytmu, porównaj ją ze Wskazówkami dotyczącymi jakości Google, – są bardzo wymowne, jeśli chodzi o potrzeby wyszukiwarek.
Czego chcą wyszukiwarki?
Wyszukiwarki zawsze chciały tego samego: udzielać właściwych odpowiedzi na pytania szukającego w najbardziej pomocnym formacie. Jeśli to prawda, dlaczego wydaje się, że SEO różni się teraz niż w poprzednich latach?
Pomyśl o tym jak o osobie uczącej się nowego języka.
Na początku znajomość języka przez tę osobę jest bardzo niewielka lub zerowa. Jednak z czasem zrozumienie nowego języka zaczyna się pogłębiać i uczy się semantyki – znaczenia stojącego za językiem oraz relacji między słowami i frazami. W końcu, przy wystarczającej praktyce, uczeń zna język wystarczająco dobrze, aby nawet zrozumieć niuanse, i jest w stanie udzielić odpowiedzi na nawet niejasne lub niepełne pytania.
Gdy wyszukiwarki dopiero zaczynały się uczyć naszego języka, znacznie łatwiej było ograć system, stosując różnego rodzaju sztuczki, które w rzeczywistości są niezgodne z wytycznymi dotyczącymi jakości. Weźmy na przykład upychanie słów kluczowych. Jeśli chciałeś uzyskać pozycję dla określonego słowa kluczowego, takiego jak „śmieszne żarty”, możesz dodać kilka razy słowa „śmieszne żarty” oraz je “zboldować” (pogrubić) z nadzieją na podniesienie pozycji w rankingu dla tego hasła:
“Witamy w zabawnych dowcipach! Opowiadamy najśmieszniejsze żarty na świecie. Śmieszne żarty są zabawne i szalone. Twój śmieszny żart czeka. Usiądź wygodnie i czytaj śmieszne dowcipy, ponieważ śmieszne żarty mogą sprawić, że będziesz szczęśliwy i zabawny.”
Powyższa taktyka zapewniała okropne doświadczenia użytkowników (UX), ludzie zamiast śmiać się ze śmiesznych żartów, byli bombardowani irytującym i trudnym do odczytania tekstem. Działało to w przeszłości, jednak wyszukiwarki nigdy tego nie chciały.
Rola jaką linki odgrywają w SEO
Kiedy mówimy o linkach, możemy mieć na myśli dwie rzeczy: „linki przychodzące” to linki z innych stron internetowych, które prowadzą do Twojej witryny, podczas gdy “linki wewnętrzne” to linki w Twojej witrynie, które prowadzą do innych stron (w tej samej witrynie).
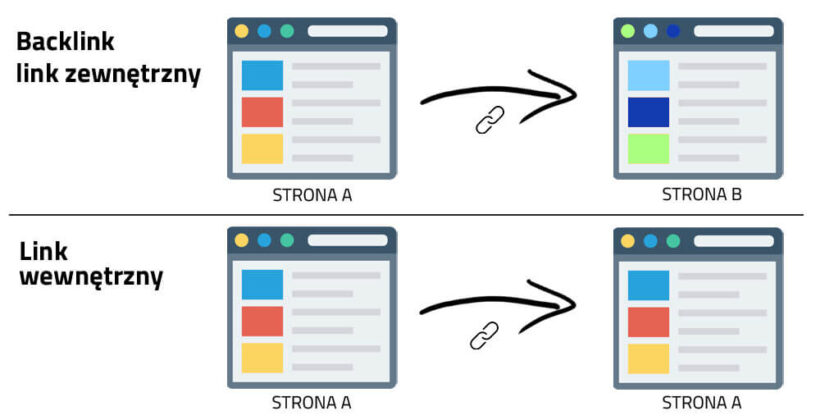
Patrząc wstecz, linki odgrywały bardzo dużą rolę w SEO. We wczesnych czasach istnienia wyszukiwarek, potrzebowały one pomocy w ustaleniu, które strony internetowe są bardziej wiarygodne i wartościowe od drugich, tak aby mogły one uszeregować organiczne wyniki wyszukiwań. Obliczanie liczby linków prowadzonych do wybranej strony pomagało im w tym.
Backlinki działają bardzo podobnie do poczty pantoflowej w prawdziwym życiu. Weźmy za przykład kawiarnię o nazwie “kawcia u Nati”. :
- Polecenia od innych – dobra oznaka autorytety
- Przykład: Wielu różnych ludzi mówiło, że kawa Natalii jest najlepsza w mieście
- Polecenia od ciebie = stronnicze, więc nie jest to dobry znak autorytetu
- Przykład: Natalia twierdzi, że jej kawa jest najlepsza w mieście
- Polecenia z nieodpowiednich lub niskiej jakości źródeł = niezbyt dobry znak autorytetu, który może nawet oznaczać Cię jako spam
- Przykład: Natalia zapłaciła za to, by ludzie, którzy nigdy nie odwiedzili jej kawiarni, mówili innym, że jej kawa jest najlepsza w mieście.
- Brak poleceń = niejasny autorytet
- Przykład: kawa Natalii może być dobra, ale nie możesz znaleźć nikogo, kto ma opinię, więc nie możesz być tego pewien.
Właśnie dlatego stworzono PageRank. PageRank (część podstawowego algorytmu Google) to algorytm analizy linków nazwany na cześć jednego z założycieli Google, Larry’ego Page’a. PageRank szacuje znaczenie strony internetowej, mierząc jakość i liczbę linków do niej wskazujących. Zakładamy, że im bardziej trafna, ważna i godna zaufania jest strona internetowa, tym więcej linków uzyska.
Im więcej masz naturalnych linków zwrotnych z witryn o wysokim autorytecie (zaufanych), tym większe szanse na wyższą pozycję w wynikach wyszukiwania.
Jaką rolę treści odgrywają w SEO?
Nie byłoby sensu linków, gdyby one nie przekierowywały użytkowników do czegoś. Tym czymś są treści/zawartość strony. Treść to coś więcej niż słowa; jest nimi wszystko co jest konsumowane przez użytkowników – są nimi treści wideo, treści graficzne i oczywiście tekst. Jeśli wyszukiwarki są automatami zgłoszeniowymi, treść jest środkiem, za pomocą którego wyszukiwarki te odpowiedzi udzielają.
Za każdym razem, gdy ktoś przeprowadza wyszukiwanie, istnieją tysiące możliwych wyników, więc w jaki sposób wyszukiwarki decydują, które strony wyszukiwarka uzna za wartościowe? Dużą częścią określania pozycji strony w rankingu dla danego zapytania jest to, jak dobrze treść na stronie odpowiada celowi zapytania. Innymi słowy, czy ta strona jest zgodna z wyszukiwanymi słowami i pomaga spełnić zadanie, które poszukiwacz próbował wykonać?
Ze względu na to, że koncentrujesz się na zadowoleniu użytkowników i wykonywaniu zadań, nie ma ścisłych kryteriów dotyczących tego, jak długo powinna trwać Twoja treść, ile razy powinna zawierać słowo kluczowe, ani co wstawiasz w tagach nagłówka. Wszystkie te kryteria mogą odgrywać rolę w skuteczności strony w wyszukiwaniu, ale należy skupić się na użytkownikach, którzy będą czytać treść.
Dzisiaj, z setkami, a nawet tysiącami sygnałów rankingowych, trzy pierwsze pozostają niezmiennie spójne: linki do Twojej witryny (które służą jako sygnały wiarygodności strony trzeciej), treść na stronie (jakość treści spełniająca zamierzenia osoby szukającej), oraz RankBrain.
Czym jest RankBrain?
RankBrain to element uczenia maszynowego podstawowego algorytmu Google. Uczenie maszynowe to program komputerowy, który z czasem poprawia swoje przewidywania dzięki nowym analizom zachowań użytkowników. Innymi słowy, zawsze się uczy, a ponieważ zawsze się uczy, jakość i precyzja wyników wyszukiwania z dnia na dzień się poprawia.
Na przykład, jeśli RankBrain zauważy niższy ranking URL zapewniający lepszy wynik dla użytkowników, niż adresy URL wyższego rankingu, możesz się założyć, że RankBrain dostosuje te wyniki, przenosząc bardziej trafny wynik wyżej i obniżając liczbę mniej istotnych stron, jako produktu ubocznego.
Podobnie jak teraz, w przypadku wyszukiwarki, nie wiemy dokładnie, co wchodzi w skład RankBrain, ale najwyraźniej ludzie w Google też nie.
Co to oznacza dla SEO?
Ponieważ Google będzie nadal wykorzystywać RankBrain do promowania najbardziej trafnych i pomocnych treści, musimy bardziej niż kiedykolwiek wcześniej skoncentrować się na spełnianiu celów użytkowników. Zapewnij możliwie najlepsze i najbardziej trafne informacje i doświadczenia dla użytkowników odwiedzających Twoją witrynę. Jeżeli o to zadbałeś – gratuluję! Wykonałeś pierwszy duży krok osiągnięcia dobrych wyników w RankBrain.
Wskaźniki zaangażowania: korelacja, związek przyczynowy czy oba?
W rankingach Google, wskaźniki zaangażowania najprawdopodobniej częściowo korelują, a częściowo są związkiem przyczynowym.
Gdy mówimy o danych dotyczących zaangażowania, mamy na myśli dane reprezentujące sposób, w jaki użytkownicy korzystają z Twojej witryny na podstawie wyników wyszukiwania.
Obejmuje to między innymi:
- Kliknięcia (odwiedziny z wyszukiwania)
- Czas na stronie (czas, jaki odwiedzający spędził na stronie przed jej opuszczeniem)
- Współczynnik odrzuceń (procent wszystkich sesji witryny, w których użytkownicy oglądali tylko jedną stronę)
- Pogo-sticking (kliknięcie wyniku organicznego, a następnie szybki powrót do SERP, aby wybrać inny wynik)
Wiele testów, wykazało, że wskaźniki zaangażowania korelują z wyższym rankingiem, jednak związek przyczynowy był przedmiotem gorących dyskusji. Czy dobre wskaźniki zaangażowania wskazują tylko na witryny o wysokiej pozycji? Czy witryny są wysoko w rankingu, ponieważ mają dobre wskaźniki zaangażowania?
Co powiedziało Google
Chociaż nigdy nie używali terminu „bezpośredni czynnik rankingowy”, Google jasno stwierdził, że wykorzystuje dane na temat kliknięć do modyfikowania wyników organicznych SERP dla określonych zapytań.
Według byłego szefa Google ds. Jakości wyszukiwania Udi Manbera:
„Na sam ranking wpływ mają dane kliknięcia. Jeśli odkryjemy, że w przypadku konkretnego zapytania 80% osób klika # 2, a tylko 10% klika # 1, po chwili stwierdzimy, że prawdopodobnie 2 jest tym, czego ludzie chcą, więc zmienimy go. ”
Kolejny komentarz byłego inżyniera Google Edmonda Lau to potwierdza :
„Jest całkiem jasne, że jakakolwiek rozsądna wyszukiwarka użyłaby danych o kliknięciach do własnych wyników, aby wrócić do rankingu w celu poprawy jakości wyników wyszukiwania. Rzeczywista mechanika wykorzystywania danych o kliknięciach jest często zastrzeżona, ale Google wyraźnie pokazuje, że wykorzystuje dane o kliknięciach w swoich patentach w systemach takich jak elementy treści z korekcją rangi. ”
Ponieważ Google cały czas musi poprawiać jakość wyszukiwania, wydaje się nieuniknione, że wskaźniki zaangażowania są czymś więcej niż korelacją, ale wydaje się, że Google nie nazywa wskaźników zaangażowania „sygnałem rankingowym”, ponieważ są one używane do poprawy jakości wyszukiwania, a ranking poszczególnych adresów URL jest tego produktem ubocznym.
Co potwierdzono testami
Różne testy potwierdziły, że Google dostosuje kolejność SERP w odpowiedzi na zaangażowanie wyszukiwarki:
- Test Randa Fishkina z 2014 roku spowodował, że wynik nr 7 przesunął się na pierwsze miejsce po przekonaniu około 200 osób do kliknięcia adresu URL w wynikach wyszukiwań. Co ciekawe, poprawa rankingu wydawała się być odizolowana od lokalizacji osób, które odwiedziły link. Pozycja w rankingu wzrosła w Stanach Zjednoczonych, gdzie znajdowało się wielu uczestników, podczas gdy pozostała niższa na stronie w Google Canada, Google Australia itp.
- Porównanie najlepszych stron przez Larry’ego Kima i ich średni czas przebywania przed i po RankBrain, wydawało się wskazywać, że element uczenia maszynowego algorytmu Google obniża pozycję w rankingu stron, na których ludzie nie spędzają tyle czasu.
- Testy Darrena Shawa wykazały również wpływ zachowania użytkowników na wyniki wyszukiwania lokalnego i wyniki pakietu map.
Wskaźniki zaangażowania użytkowników (UX) są wyraźnie wykorzystywane przez wyszukiwarki do dostosowania wyników organicznych w celu poprawy jakości i pozycjonowania zmian pozycji jako produktu ubocznego, można śmiało powiedzieć, że SEOwcy powinni również optymalizować strony pod kątem zaangażowania. Zaangażowanie nie zmienia obiektywnej jakości strony internetowej, raczej poprawia wartość dla użytkowników w porównaniu z innymi wynikami w Google dla tego zapytania. Właśnie dlatego, po braku zmian na stronie lub braku linków zwrotnych (backlinków), może ona spaść w rankingu, jeśli zachowania użytkowników wskazują, że preferują odwiedzać i przeglądać inne strony (Twoich konkurentów).
Jeśli chodzi o ranking stron internetowych, wskaźniki zaangażowania działają jak sprawdzanie faktów. Czynniki obiektywne, takie jak linki i treść, zajmują pierwsze miejsce na stronie, a następnie wskaźniki zaangażowania pomagają Google finalnie doprecyzować i wyświetlić najbardziej trafne wyniki
Ewolucja wyników wyszukiwań
W czasach, gdy wyszukiwarkom brakowało wyrafinowania, jakie mają dzisiaj, termin „10 niebieskich linków” został wymyślony w celu opisania płaskiej struktury SERP. Za każdym razem, gdy przeprowadzono wyszukiwanie, Google zwraca stronę z 10 bezpłatnymi wynikami, każdy w tym samym formacie.
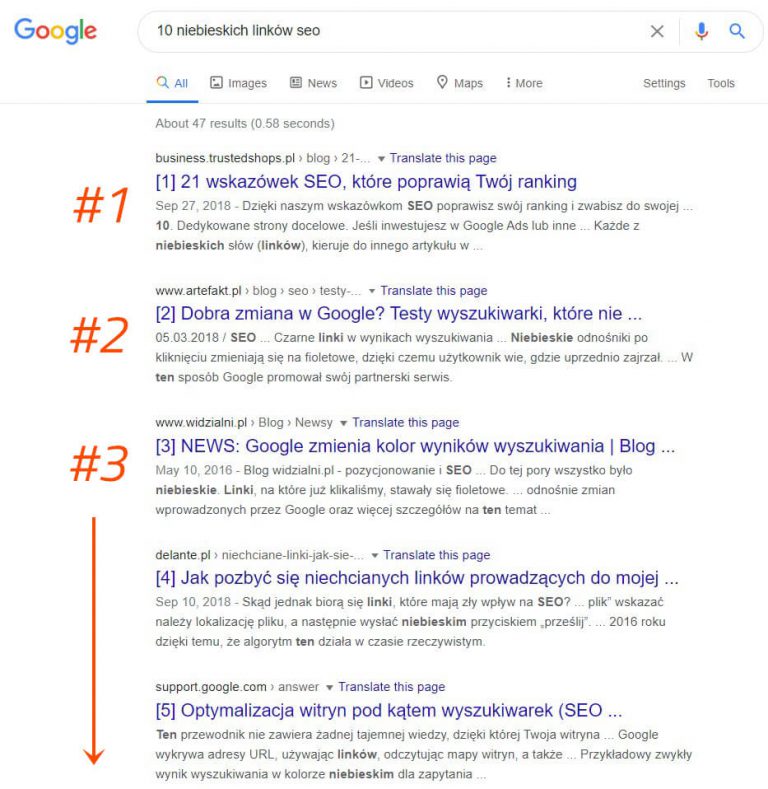
W tym krajobrazie poszukiwań, miejsce nr 1 było świętym graalem SEO. Jednak później nagle… coś się zmieniło. Google zaczął dodawać wyniki w nowych formatach na swoich stronach wyników wyszukiwania, zwane dodatkami czy funkcjami SERP. Niektóre z tych funkcji SERP obejmują:
- Reklamy płatne
- Featured snippets
- People Also Ask boxes
- Local (map) pack
- Knowledge panel
- Sitelinks
Google wciąż się rozwija i ewoluuje udoskonalając dodatki i co jakiś czas dodaje nowe. Eksperymentowali nawet z „SERP o zerowym wyniku”, zjawiskiem, w którym tylko jeden wynik istnieje bez żadnych wyników poniżej, z wyjątkiem opcji „zobacz więcej wyników”.
Dodanie tych funkcji wywołało początkową panikę z dwóch głównych powodów. Po pierwsze, wiele z tych funkcji spowodowało, że wyniki organiczne zostały zepchnięte na kolejny plan. Innym skutkiem ubocznym jest to, że mniej użytkowników klika wyniki organiczne, ponieważ znajdują oni odpowiedź bezpośrednio w wyszukiwarce
Dlaczego Google miałby to zrobić? Wszystko wraca do wyszukiwania. Zachowanie użytkownika wskazuje, że niektóre zapytania są lepiej zaspokajane przez różne formaty treści. Zauważ, jak różne typy funkcji SERP pasują do różnych typów zamiarów zapytań.
| Cel zapytania |
Możliwy dodatek SERP (Feature Snippet), który się wyświetli |
| Informacyjne |
Dodatek feature snippet |
| Informacyjne z jednym wynikiem |
Knowledge Graph / instant answer |
| Lokalne |
Mapka |
| Transakycjne |
Reklamy shopping ads |
W rozdziale 3 porozmawiamy więcej o zamiarach, jednak aktualnie ważne jest, aby wiedzieć, że odpowiedzi mogą być udzielane osobom szukającym w wielu różnych formatach, a sposób, w jaki tworzysz treść, może wpływać na format, w jakim będą one wyświetlane w wynikach wyszukiwania.
Lokalne wyszukiwanie
Wyszukiwarka taka jak Google ma własny indeks wykazów firm lokalnych, na podstawie którego tworzy wyniki wyszukiwania lokalnego.
Jeśli wykonujesz lokalne SEO dla firmy, która ma fizyczną lokalizację, i którą klienci mogą odwiedzić (np. dentystę czy prawnika) lub dla firmy, która podróżuje, aby odwiedzić swoich klientów (np. hydraulik), upewnij się, że zweryfikujesz i zoptymalizujesz bezpłatne wpisy w Google Moja Firma.
Jeśli chodzi o lokalne wyniki wyszukiwania, Google wykorzystuje trzy główne czynniki do ustalenia rankingu:
- Stosowność
- Dystans
- Rozgłos
Związek z tematem (trafność)
Trafność polega na tym, jak dobrze lokalna firma odpowiada temu, czego szuka użytkownik. Aby upewnić się, że firma robi wszystko, co w jej mocy, aby była odpowiednia dla wyszukiwarek, upewnij się, że informacje o firmie są dokładnie i rzetelnie uzupełnione.
Dystans
Google wykorzystuje Twoją lokalizację geograficzną, aby lepiej wyświetlać wyniki lokalne. Lokalne wyniki wyszukiwania są bardzo wrażliwe na bliskość, która odnosi się do lokalizacji użytkownika i / lub lokalizacji określonej w zapytaniu (jeśli wyszukiwarka ją zawierała np. hydraulik Kraków).
Organiczne wyniki wyszukiwania są wrażliwe na lokalizację wyszukiwarki, choć rzadko tak wyraźne, jak w wynikach pakietu lokalnego (mapce Google z wynikami lokalnymi).
Celność
Wyróżniając się jako czynnik, Google chce nagradzać dobrze znane znane firmy w realnym świecie. Oprócz znaczenia firmy w trybie offline, Google sprawdza również niektóre czynniki online w celu ustalenia lokalnego rankingu, takie jak:,
Opinie
Liczba recenzji Google, które otrzyma lokalna firma ma znaczący wpływ na ich pozycję w lokalnych wynikach wyszukiwania.
Wzmianki/odniesienia o firmie
„wzmianki o firmie” lub „wykaz firm” to internetowe odwołanie do lokalnego „NAP” (nazwa, adres, numer telefonu) lokalnej firmy na zlokalizowanej platformie (Yelp, Acxiom, YP, Infogroup, Localeze itp.) .
Na lokalne rankingi wpływa liczba i spójność cytatów z lokalnych firm. Google pobiera dane z wielu różnych źródeł w celu ciągłego tworzenia indeksu lokalnych firm. Gdy Google znajdzie wiele spójnych odniesień do nazwy firmy, lokalizacji i numeru telefonu, wzmacnia to „zaufanie” Google do tego jak ważne są te dane. Prowadzi to następnie do tego, że Google jest w stanie pokazać firmę z większym stopniem pewności. Google wykorzystuje również informacje z innych źródeł w Internecie, takich jak linki i artykuły.
Ranking organiczny
Najlepsze praktyki SEO dotyczą również lokalnego SEO, ponieważ Google określa pozycję witryny w bezpłatnych wynikach wyszukiwania przy ustalaniu lokalnego rankingu.
Lokalne zaangażowanie
Chociaż nie jest wymieniony przez Google jako lokalny czynnik rankingowy, rola zaangażowania będzie się zwiększać w miarę upływu czasu. Google nadal wzbogaca wyniki lokalne, uwzględniając rzeczywiste dane, takie jak popularne czasy odwiedzin i średnia długość odwiedzin …
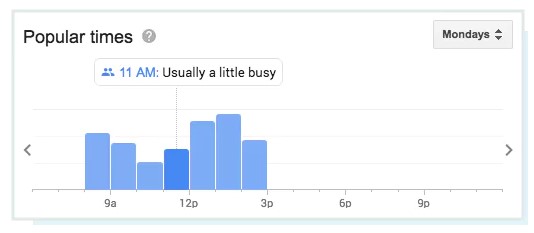
… a nawet zapewnia osobom wyszukującym możliwość zadawania pytań odnośnie tej firmy!

Niewątpliwie teraz bardziej niż kiedykolwiek wcześniej na wyniki lokalne wpływ mają rzeczywiste dane. Ta interaktywność polega na tym, w jaki sposób użytkownicy wchodzą w interakcje z lokalnymi firmami i reagują na nie, a nie wyłącznie na informacje statyczne, takie jak linki i wzmianki.
Ponieważ Google chce dostarczać wyszukiwarkom najlepsze, najtrafniejsze lokalne firmy, warto w nich korzystać z wskaźników zaangażowania w czasie rzeczywistym, aby określić jakość i trafność.
Nie musisz znać tajników algorytmu Google (pozostaje tajemnicą!), Ale do tej pory powinieneś mieć doskonałą wiedzę na temat tego, jak wyszukiwarka znajduje, interpretuje, przechowuje i klasyfikuje zawartość. Uzbrojeni w tę wiedzę, dowiedzmy się o wyborze słów kluczowych, na które będą kierowane treści w Rozdziale 3 (Badanie słów kluczowych)!
A jeżeli chcesz wrócić do podstaw: zobacz nasz poradnik seo od początku